Il est difficile en 2020 de parler de gestion des données sans parler de Big Data ou de Cloud. C’est toutefois un concept dans lequel beaucoup de choses se mélangent et où il existe de nombreuses idées préconçues. Notre équipe a donc voulu faire le tri pour vous expliquer ce qu’est le Big Data et surtout, quels enseignements les PME peuvent en tirer pour améliorer leur gestion des données.
Big Data, données massives… On décrypte!
Big Data, données massives, mégadonnées : entendons-nous bien, ces termes veulent dire la même chose. Ils représentent des ensembles très volumineux de données composés de jeux de données complexes provenant de plusieurs sources, souvent nouvelles. À cause de ses propriétés, le Big Data ne peut pas être traité par des logiciels traditionnels de gestion des données. Prenons donc le temps d’éclaircir certains points!
Les données en Big Data
Un jeu de données est un ensemble d’informations organisées dans un tableau, comme dans un fichier Excel. C’est, par exemple, une liste de contacts avec, pour chaque personne, un numéro de téléphone, une adresse courriel ou une date d’inscription qui correspond à sa situation. Les données de cet ensemble peuvent provenir de plusieurs sources de données. CRM, ERP, logiciel d’inventaire ou encore plateforme de courriel marketing, de nombreux outils peuvent fournir des informations. Dans un contexte de Big Data, imaginez-vous alors des millions de fiches clients dont les informations proviennent de plus d’une centaine de sources de données différentes. Ça donne le vertige!
Les 3V du Big Data
On touche alors à la première propriété du Big Data : le volume. Des données, il s’en développe tous les jours dans le monde entier. Pour vous donner une idée… on estime qu’il s’en crée 2,5 trillions d’octets au quotidien! Oui, au quotidien! Ces données ne sont bien sûr pas toutes les mêmes. Ventes en magasin, coordonnées GPS ou messages que nous envoyons, il existe beaucoup de catégories de données. C’est donc la seconde propriété du Big Data : la variété. Que ce soit par les sources, les formes ou les catégories, le Big Data jongle entre des informations très différentes pour ressortir des résultats et analyses intéressantes. Là où ces observations sont pertinentes, c’est qu’elles permettent de mieux comprendre des phénomènes pour prendre de meilleures décisions. Pour que ces décisions soient les plus actuelles possible, il faut que les données et les informations se créent au quotidien, et ce, de manière rapide. C’est donc la troisième propriété du Big Data : la vélocité (ou la vitesse). La fréquence de création, de traitement et d’analyse des informations doit être maximisée dans un contexte de données massives.
Le volume, la variété et la vélocité forment alors ce que l’on appelle les 3V du Big Data.
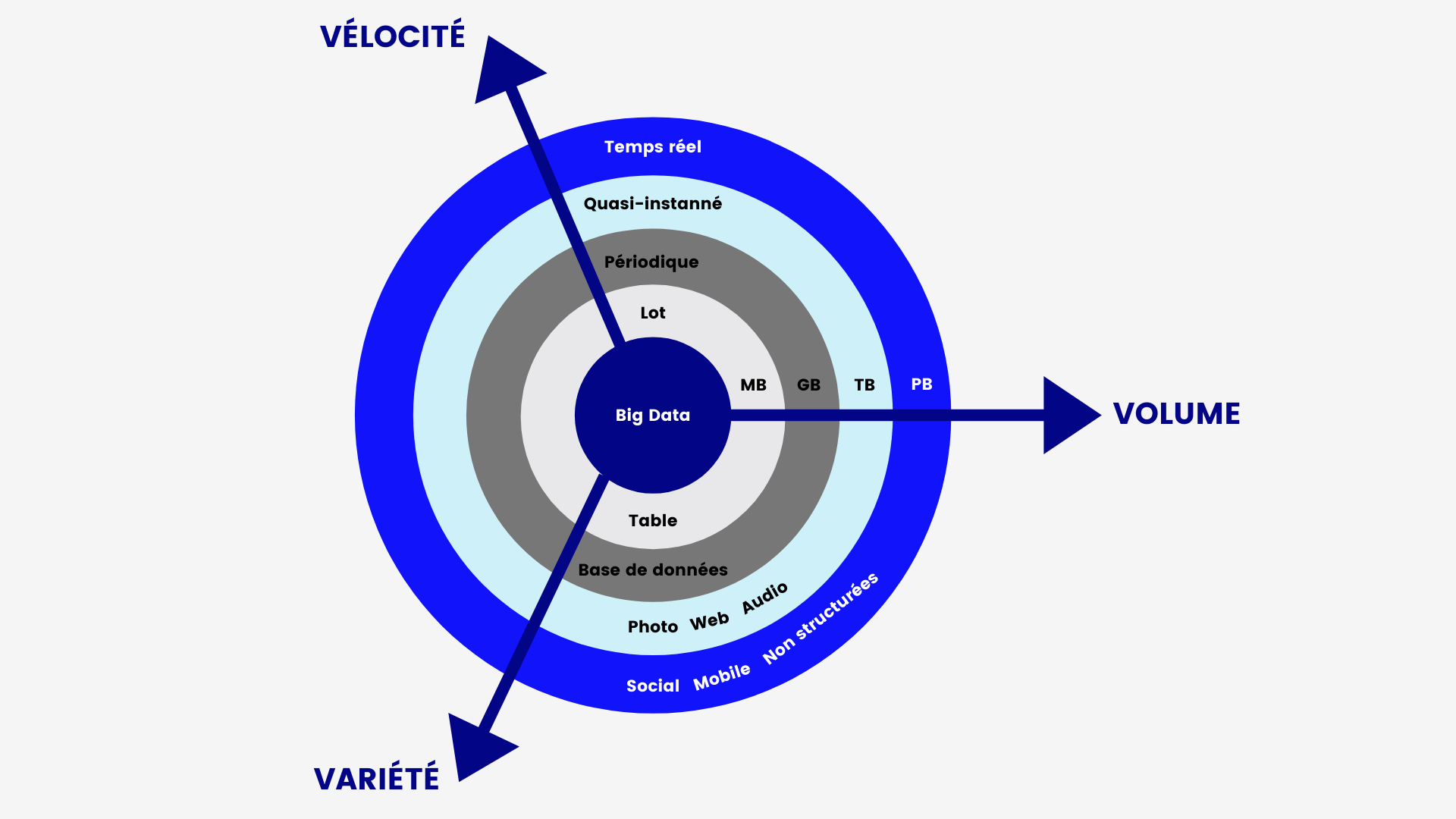
Les 3V des données massives – Adaptation de Data Science Central
Deux enjeux majeurs découlent de ces 3V : l’intelligence d’affaires et le stockage des données. Survolons ensemble ces concepts!
L’intelligence d’affaires
L’intelligence d’affaires (business intelligence) comprend la collecte, l’exploitation et l’analyse de données servant à la prise de décision. Généralement, les analystes de données ne s’occupent pas beaucoup des infrastructures technologiques, ils sont plus responsables des données en tant que telles. Ce sont à eux que vous pourriez demander un rapport sur les performances de vos différents magasins. Leur rôle est de trier dans les bases de données les informations, de les faire communiquer entre elles grâce à des calculs et de vous fournir des résultats qui appuient vos décisions. Plus spécifiquement, voici leurs missions :
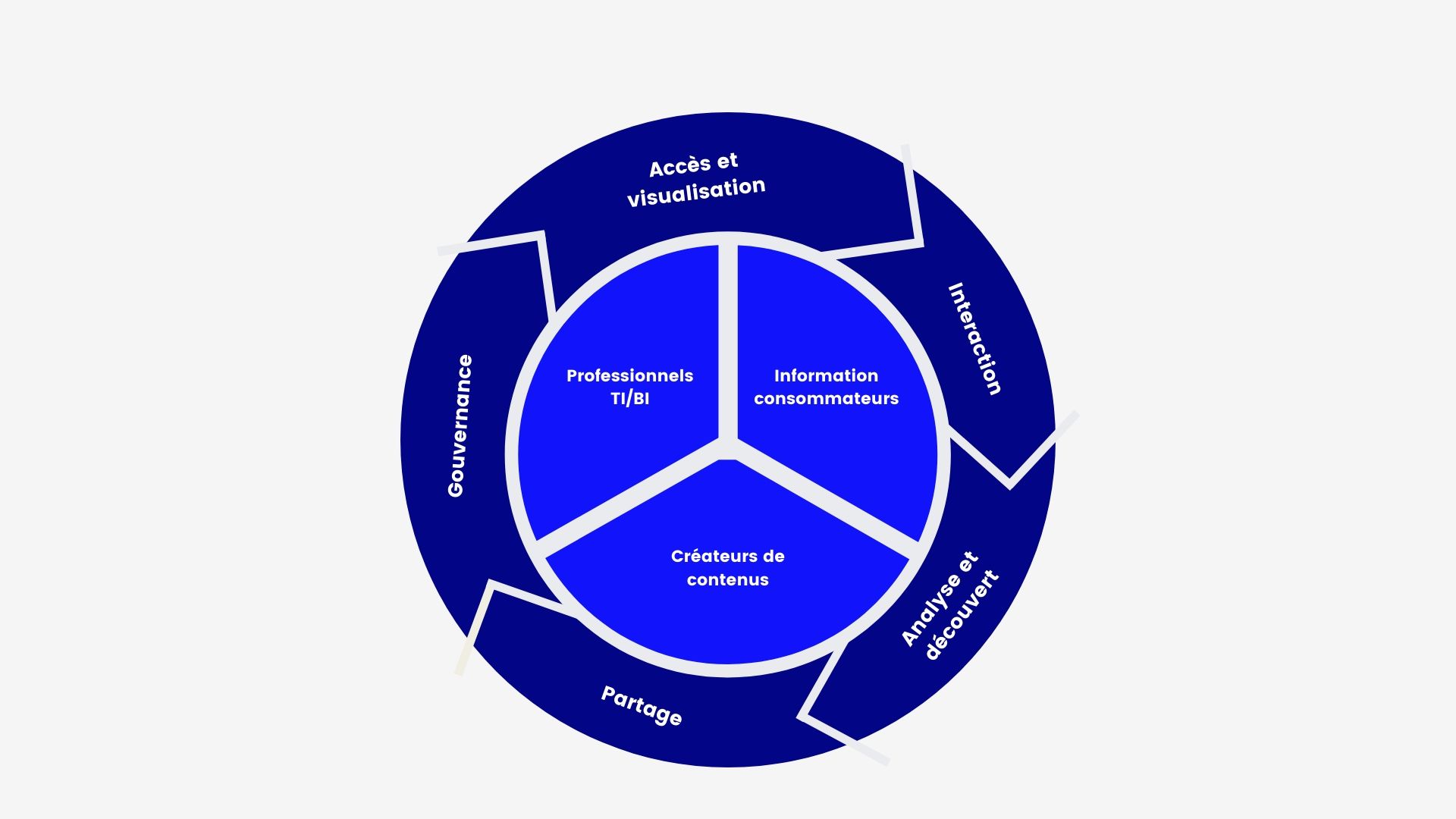
Le processus d’intelligence d’affaires – Adaptation de Tableau
Dans un contexte de données massives, ces scientifiques de la donnée misent sur l’analyse pour découvrir de nouvelles choses ou faire avancer les stratégies de l’entreprise. Ils s’appuient notamment sur les analyses prédictives. Ces dernières sont au cœur du Big Data. Elles consistent à pratiquer des algorithmes sur des données afin d’anticiper de probables résultats. Pour y arriver, elles mélangent des tactiques statistiques et des éléments d’apprentissage automatique (machine learning). Ah oui… on avait oublié de préciser : le Big Data et l’intelligence artificielle (IA) sont intimement liés. En absorbant un volume exponentiel de données (Big Data), l’intelligence artificielle est capable de faire évoluer les algorithmes et les prédictions. C’est ce que l’on appelle le Machine Learning. De plus en plus, l’intelligence artificielle peut aussi utiliser les données massives (Big Data) pour entraîner l’ordinateur à prendre des décisions de manière autonome. Mais ici, on tombe dans ce que l’on nomme le Deep Learning. On vous évitera les détails… l’idée est juste de vous montrer que l’on peut avoir beaucoup de niveaux différents quand on parle de Big Data et d’intelligence d’affaires.
La responsabilité du volume
L’intelligence d’affaires est responsable du traitement des données pour les analyser. On pourrait penser que son objectif est d’accumuler le plus d’informations possible pour démultiplier les calculs et les observations. Pourtant, on tend aujourd’hui à l’inverse. Trop de données peut devenir dangereux pour les performances des structures informatiques. C’est pourquoi l’intelligence d’affaires se dote de la responsabilité de maximiser les informations et de les recentrer sur l’essentiel. Dans notre article sur la gestion des données, nous abordons toute cette notion stratégique derrière les données. Nous vous invitons à le lire pour aller plus dans cette discussion!
C’est en abordant le sujet du volume que l’intelligence d’affaires vient alors se greffer au second enjeu, celui du stockage.

Le stockage des données
Les différentes solutions
Dans notre article sur les outils de la gestion de données, nous abordons plusieurs outils qui peuvent être utilisés pour stocker des informations dans une entreprise. Pour un contexte de Big Data, il est important de savoir que les bases de données que l’on utilise fonctionnent sur le principe du NoSQL, comme la solution open source Hadoop. Dans un contexte où l’on ne traite qu’avec des données structurées, on utilise aussi des entrepôts de données (data warehouse). Cette discussion reste toutefois très « applicative ». Au-dessus de ces solutions se situe la question de leur hébergement. Et dans un contexte de Big Data, c’est tout un défi!
L’hébergement Web désigne le fait de stocker sur des serveurs sécurisés des solutions applicatives et logiciels. En effet, votre site internet, votre ERP ou votre système de courriel interne doit être hébergé sur un serveur quelconque pour fonctionner! Les centres de données (data center) sont les endroits physiques où l’on rassemble les « machines » (serveurs, routeurs, disques durs, etc.) nécessaires au stockage des données. Il en existe de très nombreux autour du monde… comme Libéo!
Plusieurs solutions d’hébergement sont disponibles en fonction du contexte dans lequel on se trouve. Des formules plus traditionnelles, comme l’hébergement mutualisé, dédié ou VPS, sont suffisantes quand on a relativement peu de données à stocker ou que le trafic sur les applications reste peu important. Avec l’essor du Big Data et des technologies, on parle aussi des solutions d’hébergement infonuagique… le fameux Cloud!

L’intérieur d’un centre de données – Visuel de Tech Republic
L’émergence du Cloud, de quoi parle-t-on ?
Le Cloud a fait l’effet d’une bombe lors de son apparition aux débuts des années 2010. On a même parlé d’innovation de rupture! Mais le Cloud, c’est quoi au juste?
Un hébergement est dit infonuagique (Cloud) lorsque les données sont stockées non pas sur des machines dédiées, mais sur des machines mutualisées. Autrement dit, vous devez louer une partie d’un équipement informatique. Le but est de vous apporter une plus grande flexibilité, et surtout, une plus grande sécurité. Vous pouvez choisir entre trois solutions Cloud : privé, public ou hybride. Vous connaissez peut-être Amazon Web Service (AWS), Microsoft Azure ou Google Cloud. Ce sont les plus grandes solutions Cloud publiques. Après une ruée vers les Cloud publics, beaucoup d’entreprises reviennent aujourd’hui à des solutions hybrides. Il existe plusieurs entreprises au Québec à proposer ces solutions privées ou hybrides, dont Libéo.
Le choix de la solution d’hébergement est important dans un contexte de Big Data. Il était essentiel que l’on s’arrête quelques instants pour en parler!
Les autres considérations importantes
Pour terminer cette discussion autour du Big Data, il est important de parler de deux autres sujets qui lui sont liés : l’environnement et l’éthique. En effet, le Big Data n’est pas relié qu’à des questions technologiques!
L’aspect écologique du Big Data
L’essor du Big Data a entraîné une croissance importante du nombre de centres de données tout autour de la planète. Ces centres consomment toutefois beaucoup d’énergie pour fonctionner et refroidir les machines. La question environnementale des données tend alors aujourd’hui à devenir un enjeu majeur. Selon Gartner, de nombreux data centers cherchent actuellement à rationaliser leur consommation et à se tourner vers les énergies renouvelables.
La réduction énergétique, elle, passe aussi par la rationalisation des données qui circulent dans les entreprises. Avoir trop de données stockées peut diminuer les performances des outils d’analyse et de traitement, mais il n’y a pas que ça! Diminuer le nombre d’informations est aussi une question environnementale. Pensez-y!
La question de l’éthique
Enfin, l’éthique est bien sûr une question importante du Big Data. Jusqu’où peut-on aller avec les données? Quelles sont les limites éthiques de l’intelligence artificielle? Que peut-on collecter sur les personnes? Doit-on revendre les données sur nos clients? Beaucoup de questions sont à se poser! Pour mener à bien cette réflexion, le Big Data ne peut plus aller sans la gouvernance des données.

Ce que vous devriez retenir…
À l’heure actuelle, le traitement de données massives (ou Big Data) est encore réservé aux très grandes entreprises, comme Facebook ou Google. Toutefois, le concept tend à se démocratiser et il est intéressant pour une PME de s’y intéresser pour avoir une réflexion à long terme sur sa gestion des données.
Dans cet article, nous avons survolé avec vous le concept de Big Data et certains de ses enjeux. Ce que vous devriez retenir? Que le Big Data orbite autour du volume, de la vélocité et de la variété. À votre niveau, vous pouvez aussi réfléchir à l’intégration de ces piliers dans votre gestion des données!